I Learnt About The Different Pathfinding Algorithms & Made A Tool In C++. Here's My Process.
Pathfinding algorithms have always been something which interests me, and so I decided to make myself a pathfinding tool!
Published on January 10, 2022 by Amy Elliott
C++ Programming Algorithms Project-Based Learning University
30 min READ
Proposal
For the project, I wrote a proposal, and for this proposal document, I include many things, like the concept of what I will be doing, and videos and photographs or programs which inspire me.
I also write an evaluation on how I’m going to tackle this project, including the different libraries and skills I would need for this and how I think I’m going to approach the project, with a bibliography section at the bottom for all researched resources I am going this use. This would involve primary and secondary research.
Here are the important parts of my proposal:
Concept
The bare minimum I wanted to do was produce a graph from inputted values and my code would find a path from point x to y.
My extended task is to make a handful of ‘maps’ with certain characters being certain things, like ‘X’ being a wall and ‘.’ Being an empty spot. I would let the user input the directory of any map, and even their own custom maps, and then the program would output the shortest route to the finish point.
If I’m able to finish this project quickly and I have some extra time, I have the idea to visualize the program using OpenGL with simple squares for each space in the map, an empty square would be white and a wall would be black, and then I could have the process of the pathfinding make the squares glow up the shortest route.
Software/Sources Needed
There are a few software and sources which came in handy to use throughout the project these include but aren’t limited to:
| Tool/Software | Reason For Use |
|---|---|
| Microsoft Word/PowerPoint | Planning documents |
| Trello & Tape | Project management |
| WordPress | Writing development blog |
| YouTube | Inspiration, research & study |
| C++ Documentation / Books | Any C++ help I need |
| OpenGL Documentation | Any OpenGL help I need |
| General help | |
| Zotero | Manage all my sources for the bibliography |
| Programming Game AI By Example (Book) | Study graph theory and algorithms |
Action Plan
I find it very useful to make action plans, as it helps me make sure I stay on track and don’t spend too long on a specific task. As I only had a few weeks to work on this, I made sure that my action plan was that long.
| Week | Plan |
|---|---|
| 1 | Prototype something! (Prototypes Page) |
| 2 | Plan a project. (Research Page) |
| 3 | Project Work (Development Log) |
| 4 | Project Work (Development Log) |
| 5 | Project Work (Development Log) |
| 6 | Project Work (Development Log) |
| 7 | Finish Project - Project Work (Development Log) |
| 8 | Tidy Project - Project Polish/Cleaning (Development Log), Evaluation (Evaluation Page) |
| 9 | Evaluation (Evaluation Page), Document |
| 10… | Document |
Research
I wasn’t going to go straight into the final project when starting this, because prototypes are really important to make sure you’re doing everything right! This was the first part of the research I have done.
Read & Sort Input From Text Files
For my first prototype, I was hoping to find the path by using a maze that was made with a text file, so I would need to learn how to read and output any text file. I was then hoping to sort these file contents into something I can use with pathfinding.
To learn how to read files, I have done some googling into how it works, and I found out that it was very easy to do!
To sort the file contents, I needed to think about how I should store them. I did planning into what class structure would work best for each space in the map, and I also researched into 2D arrays as these seemed like the best way to store the nodes at the time.
Sorting Algorithms
I looked into how I can find the shortest route to the end position, and how I can check if my inputted maze was valid.
From this, I read up on Breadth-First Search, Depth First Search, A*, and Dijkstra’s Algorithm.
Out of all of these algorithms, and with the timeframe I had for this project, I decided that I should put A* and Dijkstra’s Algorithm aside for now, so I can study Breadth/Depth First Search, another reason for picking these algorithms is because it would be overkill to use A*/Dijkstra’s because my mazes really wouldn’t be too large so the slower execution times of Breadth/Depth-First search is nothing to worry about.
Problem Solving & Prototyping
Getting The Maze & Outputting
I started my prototype by outputting the lines which were on the maze in the text file which I had made.
int lineCount = 0;
string line;
ifstream route(".../maze.txt");
while(getline(route, line))
{
cout << line << endl;
++lineCount;
}
cout << "Number of lines is: " << lineCount << endl;User Input
This was the change I made to the first few lines so the user can put in whatever maze they want to put in, even their own made up mazes!
cout << "Input a maze file directory: ";
cin >> directory;
ifstream route(directory);Output
xxxxx
xA...Bx
xxxxxxx
Number of lines is: 3For Loop (Checking Everything Is Working)
I then ran a for loop which printed out what each space was, so I can check the output and make sure it’s correct.
for(int i = 0; i < map_length; i++)
{
switch(line[i])
{
case 'x':
cout << "WALL!" << endl;
break;
case '.':
cout << "Empty" << endl;
break;
case 'A':
cout << "Start Point" << endl;
break;
case 'B':
cout << "End Point" << endl;
break;
}
}Making a 2D Array
I began thinking how I can organize my data to work like a 2D map. And I thought a 2D array would work the best, and I can treat the 2D array like X and Y coordinates. I used for loops to go through each character in each line and set its value.
char mapPoints[10][10];
for(int i = 0; i < 9; i++)
{
//for each individual character in the array
mapPoints[i][k] = line[k];
cout << line[k];
}
//for each line in the array
cout << endl;
lineCount++;Storing X & Y Coordinates For The Start & End Points
switch(line[k])
{
case 'A':
x_startPoint = k;
y_startPoint = i;
break;
case 'B':
x_endPoint = k;
y_endPoint = i;
break;
}Difference Between Points
With the current code, I was able to calculate the difference between two coordinate points, and I did this by subtracting the x coordinate of the start and endpoint and subtracting the y coordinate of the start and endpoint, but this didn’t take obstacles into consideration.
cout << "Difference between: " << "(" << difference(x_endPoint, x_startPoint) << ", " << difference(y_endPoint, y_startPoint) << ")" << endl;Space Class
I needed to check the state of a node, and so I decided to make a space class for each space in the maze. Looking back now, I should’ve called this ‘node’. This class would check if it’s a wall, if it’s been visited and what its x and y coordinates are.
class space
{
public:
bool isWall;
bool isVisited;
int x_Space;
int y_Space;
space()
{
isWall = false;
isVisited = false;
x_Space = 0;
y_Space = 0;
}
}How Can I Proceed?
At this point, I got stuck on how I could implement BFS.
So… I decided to start everything again as there had to be a better way to do this! I knew I was getting way too ahead of myself. I found a book called ‘Programming Game AI by Example’ and used this to aid me with my research.
Back To The Drawing Board!
Graph Data Structures
Following my failed pathfinding attempt before the assessment, I knew exactly what was wrong with my approach, so I had to do some more research into Graphs in general. I realized my mistake through presenting the pathfinding attempts to a few people who knew more about the subject and asking them for feedback, so using the book mentioned and google, I did more research into Graph Data Structures.
I’ve taken some notes as I was studying, it’s very useful for me to make these so I can reference them whenever I’m stuck on remembering something about graphs later on. These notes were taken from Chapter 5 of Programming Game AI by Example. This section of the book covered the basics of using graph data structures in code, it covered it in a great amount of detail that I didn’t have to do much further research into graph data structures after this.
Searching Algorithms
Now I had more of an understanding of how to deal with each node in a graph, a lot more began making sense after studying graph data structures!
This was a major turning point within the project.
Breadth First Search Study
I did lots of googling into BFS and I watched a lot of videos on pathfinding to see exactly how it works. Doing this research taught me about Adjacency Lists and Adjacency Matrices and their importance within a pathfinding algorithm like this. It also taught me about queueing and what the terms ‘FIFO’ (First in first out) and ‘LIFO’ (Last in first out) meant.
“An adjacency list is a collection of unordered lists used to represent a finite graph. Each unordered list within an adjacency list describes the set of neighbors of a particular vertex in the graph.” (‘Adjacency List’, 2021)
Production
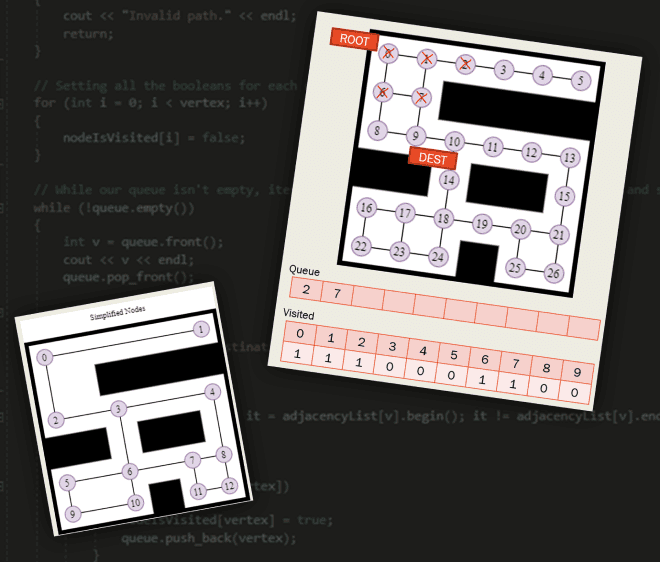
This is where based upon the new stuff I’ve learned, I would change up my approach a bit, and instead of using a text file with crosses and dots as a maze I would draw out the maze, and use different data in the text file.
So, I drew out a maze to help me visualize this, and on this maze, I would need to put nodes on each important point of the maze.
Simplified Nodes
There was 2 options when putting in nodes, the first option is that I can make very simplified node points like this:
The pros of having simplified nodes are it would be faster! And the adjacency list for this would be much smaller as there are fewer contact points!
But this comes with the cons of it obviously being simplified so if this was made for a game, it wouldn’t feel as realistic as there are fewer walking points within the maze, this concept is similar to increasing the subdivisions in a model!
Advanced Nodes
The other option is to add more nodes, to have more points on the maze!
This would give much more realistic movement if this was a player navigating a maze as there are many more points to move between.
But this comes with the cons of having a massive adjacency list and being slower to execute as there are more nodes.
Adjacency List Text File
So, the data which would be going into the text file for the input of the maze is the adjacency lists! So, I went ahead and wrote out the adjacency list into the text file, with the format of the two connecting nodes and then ending the line for the next connecting nodes.
Adjacency List In Code
There was two functions which I wrote to make the text file work with my code:
Text Line Count Function
This function gets the adjacency list text file and counts how many lines it has, it then returns that for us to put as an input for our graph, as that is how many nodes our graph would have. But looking at this now, this wouldn’t be the number of nodes on our graph at all! Instead, I should’ve counted the nodes by the highest number on the text file.
int TextLineCount()
{
string txt;
int lines = 0;
ifstream input;
input.open("adjList.txt");
while (!input.eof())
{
getline(input, txt);
lines++;
}
return lines;
}Adjacent List Graph Function
This function takes a graph input and then uses our adjacency list text file to add all the edges onto our graph.
void adjacentListGraph(Graph g)
{
ifstream file("adjList.txt");
vector<int> roots;
vector<int> destinations;
int r, d;
while(file >> r >> d)
{
roots.push_back(r);
destinations.push_back(d);
}
for(int i = 0; i < roots.size(); i++)
{
g.addEdge(roots[i], destinations[i]);
}
}Creating The Graph Class
The graph class was one of the biggest changes I made from the prototype, and my Programming Game AI By Example book helped me with understanding how I can make the best graph class I could.
Graph Class
class Graph
{
int vertex;
list<int>* adjacencyList;
public:
Graph(int v)
{
this->vertex = v;
adjacencyList = new list<int>[v];
}
void addEdge(int fromNode, int toNode);
void BFS(Graph g, int root, int dest);
}This is my Graph Class.
In the constructor, I set the integer ‘vertex’ equal to the size we set our graph to.
I then made a new list under a private variable called ‘adjacencyList’ – This list is a list of integer values which is the length of the graphs’ inputted size.
I also define 2 methods in this Graph class.
Add Edge Function
void Graph::addEgde(int fromNode, int toNode)
{
adjacencyList[fromNode].push_back(toNode);
adjacencyList[toNode].push_back(fromNode);
}The addEdge function connects two graph nodes. We need to push back both the fromNode and toNode if we want to backtrack through the adjacency list which means going (1->5) and (5->1).
Implementing Breadth First Search
Because of the research I’ve done, implementing BFS was one of the simpler tasks. I watched a few theory videos and studied the BFS Wikipedia article to help me with the implementation.
BFS Function
void Graph::BFS(Graph g, int root, int dest)
{
bool* nodeIsVisited = new bool[vertex];
list<int> queue;
nodeIsVisited[root] = true;
queue.push_back(root);
// Checking if our inputted values are valid.
if (root >= 27 || dest >= 27 || root < 0 || dest < 0)
{
cout << "Invalid path." << endl;
return;
}
// Setting all the booleans for each node to not visited
for (int i = 0; i < vertex; i++)
{
nodeIsVisited[i] = false;
}
// While our queue isn't empty, iterate though all the edges of our current node and set it to visited
while (!queue.empty())
{
int v = queue.front();
cout << v << endl;
queue.pop_front();
if (v == dest)
{
cout << "Got to destination: " << v << " = " << dest << endl;
return;
}
for (list<int>::iterator it = adjacencyList[v].begin(); it != adjacencyList[v].end(); it++)
{
int vertex = *it;
if (!nodeIsVisited[vertex])
{
nodeIsVisited[vertex] = true;
queue.push_back(vertex);
}
}
}
}This function runs a Breadth-First Search Traversal on our graph. Starting from the parameters at the top, this function takes an input of our graph (we need something to search through!), a starting position, and an ending position.
Let’s break this down a bit!
The Function’s Variables
bool* nodeIsVisited = new bool[vertex];
list<int> queue;
nodeIsVisited[root] = true;
queue.push_back(root);Here, we make a bool, which is the visited check, and this is what each node has in our graph. And then we make a list of integers that are empty for now for our queue. And then we put our root into the queue so we don’t visit the root again.
Setting Values
for (int i = 0; i < vertex; i++)
{
nodeIsVisited[i] = false;
}Here we are simply setting all of the isVisited booleans for each node to false, so they can be visited.
Setting Values In The While Loop
int v = queue.front();
cout << v << endl;
queue.pop_front();Inside the while loop that runs while our queue isn’t empty, I made a variable called ‘v’ which sets it to the node which is at the front of the queue, and print out our current node, and pop the front node from the queue.
Checking Values
if (v == dest)
{
cout << "Got to destination: " << v << " = " << dest << endl;
return;
}
for (list<int>::iterator it = adjacencyList[v].begin(); it != adjacencyList[v].end(); it++)
{
//...
}In the same while loop, I check if ‘v’ (the variable we just set) is our destination, and if it’s not, we iterate through all the edges connected to the ‘v’ node.
Within The Iterator
for (list<int>::iterator it = adjacencyList[v].begin(); it != adjacencyList[v].end(); it++)
{
int vertex = *it;
if (!nodeIsVisited[vertex])
{
nodeIsVisited[vertex] = true;
queue.push_back(vertex);
}
}Within that iterator, I set the vertex integer to be the currently connected node I am checking, this is so I can check the status of each node, which is what I want to do next.
If the node hasn’t been visited, set the node to visited and add them onto the queue.
We repeat this process until we get to the destination node!
Video Showcase
Questions, Evaluations & Reflections
Efficiency Of Code
It’s really important to make sure your code is efficient, so I went through my code and made sure it was as efficient as possible, as well as I did some research into how to write more efficient code, in case I had missed anything, and I came across a video by James Scholz, (2019) titled: ‘Write BETTER Code! 7 Tips to Improve Your Programming Skills’ – Following the tips presented in this video, I further cleaned up my code!
Limit Function Arguments
I don’t have an example of this within my code, but an idea I had to further limit function arguments is with the BFS function, and make a class that holds all of the current inputs of the function, so that function only has one argument, but in a way, I don’t think the way I do it currently is bad either because it is quite clear what it’s asking for and making those arguments a single class may make things even more confusing.
Declaring Variables Close To Their Usage
I made sure I was doing this throughout my code, an example for seeing this is the textLineCount() function, where I’m declaring variables within the function and not at a global level, and each variable I’ve declared is close to the area which it’s being used in the code.
Functions Should Do One Thing
This was something I noticed right away! My BFS function does the breadth-first search, but it also checks if our inputted values are valid! This check would’ve been better in its own function which is called at that stage of the BFS!
Otherwise, I was efficient with my addEdge function as this only adds edge, the textLineCount is fine.
I was efficient with my adjacentListGraph function as this adds all of the edges onto our graph from the text file, but I feel I could’ve named this better.
Stop Writing Zombie Code
I made sure any unused commented-out code was deleted, to make everything clean!
I thought it would be interesting to know what other people think about this, so I made a survey to ask what they think the most important aspects of efficient code were, I also asked them why they thought that.
80% of the public thought that the most important way to write efficient code was to make functions only do one thing, and then 60% of the public thought limiting function arguments was the 2nd most important way to write efficient code.
I personally think that avoiding abbreviation of variable names and making sure functions only do one thing is the most important.
I also asked for their reasoning!
Problem Solving
Throughout the development of the project, there were a few problems that I had to solve, one of the biggest being understanding the fundamentals of graph data structures and how to write my node class. I initially made a class called ‘space class’ which had many parameters to check for each space, but through my research on Graph Theory and Path Searching Algorithms, I was able to write a Graph class that was able to do everything I needed for this program.
I was interested to see how other people would do this, so I made a survey to ask, some of their answers were great! I believe the creativity from code comes from how you structure it and the problem-solving you perform!
Professionalism
I read a blog by Punit Sharma, (2016) titled: ‘Writing Professional Code in C++’ – Following the steps presented in this blog, I was able to change my code to be more professional and understand the best coding practices. The tips I followed were:
- Indent code properly so it’s following the agreed style, this also makes it easier to read!
- Comment and Document code!
- And, an extra one - Avoid abbreviations of variable names!
I asked in the survey how other people might make their code as professional as possible – So many people are able to work on it without getting confused, there were some really good answers here!
Indentation Styles
This is very important to writing professional-looking code, and easy-to-understand code, because if the indentation is all over the place, it doesn’t look right!
Throughout the entirety of my code, I use the ‘Allman Style’ of indentation, which uses broken brackets, although sometimes on other projects, I find myself using ‘Java Style’ indentation, which uses attached brackets.
The Allman style of indentation is something which I find myself doing without thinking about it, and in my opinion, I think it looks the neatest!
Documentation
With my code, I made sure it was commented, but not too heavily as I don’t want to be commenting on anything which is very obvious! I commented on things that I thought were important to know, but I didn’t go into too much detail with these comments as I believe I have written my code out in a way that it should be easy enough to read through and understand!
Avoiding Abbreviation Of Variables
Within my work, I made sure each variable name was as descriptive as possible, without being too wordy, but I knew I missed out on a few variables which could have better names, like the integer ‘v’ in the Graph declaration which is the current vertex point, but I couldn’t use the variable name ‘vertex’ as I was already using it. In the future, I will make sure I don’t use one-letter variable names.
Initial Conclusion
Writing a Breadth-First Search (BFS) Traversal tool was great fun.
Initially, I thought doing this wouldn’t be too hard, but it soon turned out to be a great challenge to develop my knowledge and learning skills.
Realizing that I was taking the wrong approach was one of the most important and interesting mistakes I made as it led to me finding the ‘Programming Game AI by Example’ book which I’ve talked about throughout this blog, this book is now one of my favorite books, as it helped me learn so many new things, and gave me a different perspective on how I can think of graphs! This book has also made me discover my interest in learning AI in the future.
This new knowledge gained from the book allowed me to confidently write a successful BFS tool, and this is important to me as a learner, as it’s made me realize, I can code anything which I want to as long as I put in the time to study and not rush headfirst into things.
Another important experience taken from producing this is understanding more about how pathfinding works, as previously, I didn’t know too much about this, and I was using built-in tools within the game engines to make pathfinding work.
So now, having learned and applied pathfinding to a simple maze, I think I can create my own pathfinding tools for any games which I am making!
As a next step, I need to learn about other pathfinding algorithms and apply them to my code, this would allow me to compare the complexity and outcome of these algorithms and use that knowledge for any pathfinding I want to do.
Bibliography/Mentioned Sources
- Adjacency list. (2021). In Wikipedia.
- Adjacency list representation of graph Adjacency list. (n.d.). Retrieved 24 February 2021, from
- Breadth-first search. (2021). In Wikipedia.
- Buckland, M. (2004). Programming Game AI by Example. Wordware.
- cplusplus. (n.d.). Input/output with files. Retrieved 22 April 2021, from
- James Scholz. (2019, January 20). Write BETTER Code! 7 Tips to Improve Your Programming Skills.
- Parmpreet Gill. (2020, June 5). 03. Graph Data Structure Creating Adjacency List in C++ Coding Blocks.
- Sharma, P. (2016, November 14). Writing Professional Code in C++.
- W3Schools. (n.d.). C++ Files. Retrieved 22 April 2021, from
Final Conclusion
As you can see from the publish date of this blog, I’ve written this in January of 2022, around 8 months after I’ve completed this.
Within these 8 months, I’ve finished my first year of University, worked an internship at Jagex, and am currently working on a placement year at Sumo Digital, working in C++ and C# in a professional setting, so I now look back at this work and can see how much I’ve improved in my programming skills since then.
Learning about the different pathfinding algorithms has most definitely made an impact on my programming skills over those months, as, like mentioned, it made me realize that I can do and implement anything as long as I put the time in to study it, no matter how complicated it looks.
Working in a professional setting made me realize that some of the code I’ve written isn’t as professional as it can be, and something that’s been sticking out to me is the inconsistent style and naming conventions throughout the code!
Naming conventions are really important, and in my time in the industry, there is always a style guide which is stuck to which ensures that everything stays neat and easy to search through as the codebase gets bigger and bigger. The other benefit of this is that if a new person joins, it would be easier for them to pick up the code as everything is all neat and tidy!
A weakness with my approach to this is that I feel I should’ve tried to contact some professional programmers as I was doing this to get feedback on the professionalism of my code and to ask them questions.
If I were to approach something like this in the future again, I would most definitely do more research into what I’m working on to ensure I understand what I’m doing before I do it, and also talk to more people for feedback!
And from this, I know I’m going to do lots more studying into algorithms as they’re so much fun!
I’m really excited to carry on growing and improving as a programmer!